In the past I have mentioned that I am not a fan of doing lots of traditional SEO consulting for a number of reasons (mostly economic), but I still work on a few large projects from time to time. One of the great parts about working with large corporate clients is when you uncover holes in their strategy, finding areas and opportunities that they can own just by deciding to. To some degree it feels like editing the search results, just like a search engineer, seeing you will pushed upon them.
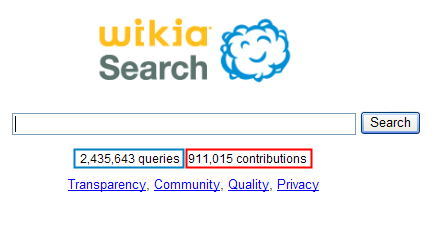
Unlike playing with Wikia Search (which only has a couple millions lifetime searches and nearly a million edits!!!) some of the changes you suggest for enterprise level sites can bring millions of high value visitors to their business free of charge.
When taking on new consulting projects you have to price with the confidence that you will be able to find something that really helps them build their business (and if you are not there is no point taking the project). At first sometimes it can seem like you set the bar too high, but when you do strong research and have a strong partner to bounce ideas off back and forth good things just happen.
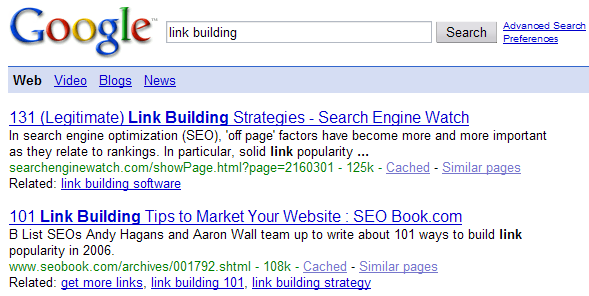
Those easy big wins are rare finds, but seem to happen on every project, just in different areas - site structure, duplicate content issues, keyword coverage, internal linking strategy, etc. Digging into a large site with fresh eyes allows you to see things that people who have been close to a project for a long time can not see. Why is that link there? Can this page rank for a couple more related queries? You end up stumbling into something that catches your eye and keep digging in until you have a good solution that earns far in excess of the consulting investment.
With affiliate and AdSense oriented sites the wins are typically much slower, smaller, and harder - sometimes requiring 6 months of effort just to get to break even, and requiring you to fight for every additional link and every additional rank. But the slow and steady path is a stronger business model for SEOs than giving clients millions of dollars of advice for a small fraction of the price. If only I knew how to talk Fortune 500 companies into giving a % of the upside, as that would make consulting so much more profitable than the slow and steady model. :)
Google hires remote quality raters part time for $15 an hour. SEOs working in client based business models usually top out somewhere in the mid 6 figure range. CEOs and some leading web publishers make deep into 7 or 8 figures a year. And some of the early Google engineers might have 9 figures worth of stock. And every one of them is getting paid in part to edit the search results. Does your business model match your ambitions?




{kind=link}